MySQL锁机制
MySQL锁机制的底层实现原理
### 锁的内存结构 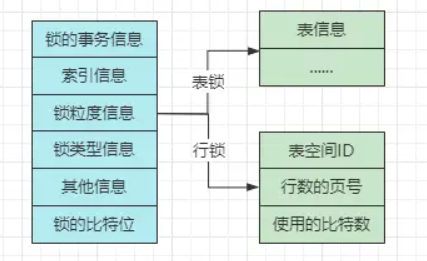 ##### 锁的事务信息 - 其中记录着当前的锁结构是由哪个事务生成的,记录的是指针,指向一个具体的事务。 ##### 索引的信息 - 这个是行锁的特有信息,对于行锁来说,需要记录一下加锁的行数据属于哪个索引、哪个节点,记录的也是指针。 ##### 锁粒度信息 - 对于不同粒度的锁,其中存储的信息也并不同,如果是表锁,其中就记录了一下是对哪张表加的锁,以及表的一些其他信息。但如果锁粒度是行锁,其中记录的信息更多,有三个较为重要的: - Space ID:加锁的行数据,所在的表空间ID。 - Page Number:加锁的行数据,所在的页号。 - n_bits:使用的比特位,对于一页数据中,加了多少个锁(后续结合讲)。 ##### 锁类型信息 - 对于锁结构的类型,在内部实现了复用,采用一个32bit的type_mode来表示,这个32bit的值可以拆为lock_mode、lock_type、rec_lock_type三部分,如下:  ##### 其他信息 - 这个所谓的其他信息,也就是指一些用于辅助锁机制的信息,比如之前死锁检测机制中的「事务等待链表、锁的信息链表」,每一个事务和锁的持有、等待关系,都会在这里存储,将所有的事务、锁连接起来,就形成了上述的两个链表。 ##### 锁的比特位 ### InnoDB的锁实现 上面已经分析了MySQL的锁对象结构,接着来设想一个问题: >如果一个事务同时需要对表中的1000条数据加锁,会生成1000个锁结构吗? 如果这里是SQL Server数据库,那绝对会生成1000个锁结构,因为它的行锁是加在行记录上的,但MySQL锁机制并不相同,因为MySQL是基于事务实现的锁,啥意思呢?来看看: - ①目前对表中不同行记录加锁的事务是同一个。 - ②需要加锁的记录在同一个页面中。 - ③目前事务加锁的类型都是相同的。 - ④锁的等待状态也是相同的。 当上述四点条件被满足时,符合条件的行记录会被放入到同一个锁结构中,好比以上面的问题为例: 假设加锁的1000条数据分布在3个页面中,同时表中没有其他事务在操作,加的都是同一类型的锁。 此时依据上述的前提条件,那在内存中仅会生成三个锁结构,能够很大程度上减少锁结构的数量。总之情况再复杂,也不会像SQL Server般生成1000个锁对象,那样开销太大了! ### MySQL获取锁的过程 当一个事务需要获取某个行锁时,首先会看一下内存中是否存在这条数据的锁结构,如果存在则生成一个锁结构,将其is_waiting对应的比特位改为1,表示目前事务在阻塞等待获取该锁,当其他事务释放锁后,会唤醒当前阻塞的事务,然后会将其is_waiting改为0,接着执行SQL。 实际上会发现这个过程并不复杂,唯一有些难理解的点就在于:事务获取锁时,是如何在内存中,判断是否已经存在相同记录的锁结构呢?还记得锁结构中会记录的一个信息嘛?也就是「锁粒度信息」,如果是表锁,会记录表信息,如果是行锁,会记录表空间、页号等信息。在事务获取锁时,就是去看内存中,已存在的锁结构的这个信息,来判断是否存在其他事务获取了锁。 拿表锁来说,当事务要获取一张表的锁时,就会根据表名看一下其他锁结构,有没有获取当前这张表的锁,如果已经获取,看一下已经存在的表锁和目前要加的表锁,是否会存在冲突,冲突的话is_waiting=1,反之is_waiting=0,而行锁也是差不多的过程。 释放锁的过程也比较简单,这个工作一般是由MySQL自己完成的,当事务结束后会自动释放,释放的时候会去看一下,内存中是否有锁结构,正在等待获取目前释放的锁,如果有则唤醒对应的线程/事务。 其实看下来之后大家会发现,MySQL的锁机制实现,与常规的锁实现有些不一样,一般的锁机制都是基于持有标识+等待队列实现的,而MySQL则是略微有些不一样。
顶部
收展
底部
[TOC]
目录
MySQL锁机制的由来与分类
MySQL共享锁与排他锁
MySQL表锁
MySQL行锁
MySQL页面锁、乐观锁与悲观锁
MySQL死锁
MySQL锁机制的底层实现原理
相关推荐
MySQL教程
MySQL命令
MySQL索引
MySQL事务
MySQL版本特性