MySQL事务
MySQL之MVCC机制
MySQL提供的锁机制确实能解决并发事务带来的一系列问题,但由于加锁后会让一部分事务串行化,而MySQL本身就是基于磁盘实现的,性能无法跟内存型数据库娉美,因此并发事务串行化会使其效率更低。因此MySQL官方在设计时,抓破脑袋的想:有没有办法再快一点!!最终,MVCC机制就诞生了,相较于加锁串行化执行,MVCC机制的出现,则以另一种形式解决了并发事务造成的问题。 ### 并发事务的四种场景 ##### 读-读场景 读-读场景即是指多个事务/线程在一起读取一个相同的数据,比如事务T1正在读取ID=88的行记录,事务T2也在读取这条记录,两个事务之间是并发执行的。 MySQL执行查询语句,绝对不会对引起数据的任何变化,因此对于这种情况而言,不需要做任何操作,因为不改变数据就不会引起任何并发问题。 ##### 写-写场景 写-写场景也比较简单,也就是指多个事务之间一起对同一数据进行写操作,比如事务T1对ID=88的行记录做修改操作,事务T2则对这条数据做删除操作,事务T1提交事务后想查询看一下,哦豁,结果连这条数据都不见了,这也是所谓的脏写问题,也被称为更新覆盖问题,对于这个问题在所有数据库、所有隔离级别中都是零容忍的存在,最低的隔离级别也要解决这个问题。 ##### 读-写、写-读场景 读-写、写-读实际上从宏观角度来看,可以理解成同一种类型的操作,但从微观角度而言则是两种不同的情况,读-写是指一个事务先开始读,然后另一个事务则过来执行写操作,写-读则相反,主要是读、写发生的前后顺序的区别。 并发事务中同时存在读、写两类操作时,这是最容易出问题的场景,脏读、不可重复读、幻读都出自于这种场景中,当有一个事务在做写操作时,读的事务中就有可能出现这一系列问题,因此数据库才会引入各种机制解决。 ##### 各场景下解决问题的方案 对于写-写、读-写、写-读这三类场景,MySQL都是利用加锁的方案确保线程安全,但上面说到过,加锁会导致部分事务串行化,因此效率会下降,而MVCC机制的诞生则解决了这个问题。 先来设想一个问题:加锁的目的是什么?防止脏写、脏读、不可重复读及幻读这类问题出现。 对于脏写问题,这是写-写场景下会出现的,写-写场景必须要加锁才能保障安全,因此先将该场景排除在外。再想想:对于读-写并存的场景中,脏读、不可重复读及幻读问题都出自该场景中,但实际项目中,出现这些问题的几率本身就比较小,为了防止一些小概念事件,就将所有操纵同一数据的并发读写事务串行化。 因此MySQL就基于读-写并存的场景,推出了MVCC机制,在线程安全问题和加锁串行化之间做了一定取舍,让两者之间达到了很好的平衡,即防止了脏读、不可重复读及幻读问题的出现,又无需对并发读-写事务加锁处理。 ### MVCC技术具体体现 假设我发布了一篇关于《MySQL事务机制》的文章,发布后挺受欢迎的,因此有不少小伙伴在看,其中有一位小伙伴比较细心,文中存在两三个错别字,被这位小伙伴指出来了,因此我去修正错别字后重新发布。 问题来了,对于文章首次发布也好,重新发布也罢,绝对要等审核通过后才会正式发布的,那我修正文章后重新发布,文章又会进入「审核中」这个状态,此时对于其他正在看、准备看的小伙伴来说,文章是不是就不见了?毕竟文章还在审核撒,因此对这个业务需求又该如何实现呢?多版本! 啥意思呢?也就是说,对于首次发布后通过审核的文章,在后续重新发布审核时,用户可以看到更新前的文章,也就是看到老版本的文章,当更新后的文章审核通过后,再使用新版本的文章代替老版本的文章即可。 这样就能做到新老版本的兼容,也能够确保文章修正时,其他正在阅读的小伙伴不会受影响,而MySQL-MVCC机制的思想也大致相同。 ### MySQL-MVCC多版本并发控制 MySQL中的多版本并发控制,也和上面给出的例子类似,毕竟回想一下,脏读、不可重复读、幻读问题都是由于多个事务并发读写导致的,但这些问题都是基于最新版本的数据并发操作才会出现,那如果读、写的事务操作的不是同一个版本呢?比如写操作走新版本,读操作走老版本,这样是不是无论执行写操作的事务干了啥,都不会影响读的事务?答案是Yes。 不过要稍微记住,MySQL中仅在RC读已提交级别、RR可重复读级别才会使用MVCC机制。 因为如果是RU读未提交级别,既然都允许存在脏读问题、允许一个事务读取另一个事务未提交的数据,那自然可以直接读最新版本的数据,因此无需MVCC介入。 同时如若是Serializable串行化级别,因为会将所有的并发事务串行化处理,也就是不论事务是读操作,亦或是写操作,都会被排好队一个个执行,这都不存在所谓的多线程并发问题了,自然也无需MVCC介入。 因此要牢记:MVCC机制在MySQL中,仅有InnoDB引擎支持,而在该引擎中,MVCC机制只对RC、RR两个隔离级别下的事务生效。 ### MVCC机制实现原理剖析 >MVCC机制主要通过隐藏字段、Undo-log日志、ReadView这三个东西实现的,因而这三玩意儿也被称为“MVCC三剑客”! ##### InnoDB表的隐藏字段 通常而言,当你基于InnoDB引擎建立一张表后,MySQL除开会构建你显式声明的字段外,通常还会构建一些InnoDB引擎的隐藏字段,在InnoDB引擎中主要有`DB_ROW_ID`、`DB_Deleted_Bit`、`DB_TRX_ID`、`DB_ROLL_PTR`这四个隐藏字段,挨个简单介绍一下。 - **隐藏主键 - ROW_ID(6Bytes)** 对于InnoDB引擎的表而言,由于其表数据是按照聚簇索引的格式存储,因此通常都会选择主键作为聚簇索引列,然后基于主键字段构建索引树,但如若表中未定义主键,则会选择一个具备唯一非空属性的字段,作为聚簇索引的字段来构建树。 当两者都不存在时,InnoDB就会隐式定义一个顺序递增的列ROW_ID来作为聚簇索引列。 因此要牢记一点,如果你选择的引擎是InnoDB,就算你的表中未定义主键、索引,其实默认也会存在一个聚簇索引,只不过这个索引在上层无法使用,仅提供给InnoDB构建树结构存储表数据。 - **删除标识 - Deleted_Bit(1Bytes)** 对于一条delete语句而言,当执行后并不会立马删除表的数据,而是将这条数据的Deleted_Bit删除标识改为1/true,后续的查询SQL检索数据时,如果检索到了这条数据,但看到隐藏字段Deleted_Bit=1时,就知道该数据已经被其他事务delete了,因此不会将这条数据纳入结果集。 设计Deleted_Bit这个隐藏字段的好处是什么呢?主要是能够有利于聚簇索引。 如果执行delete语句就删除真实的表数据,由于事务回滚的问题,就很有可能导致聚簇索引树发生两次结构调整,这其中的开销可想而知,而且先删除,再回滚,最终树又变成了原状,那这两次树的结构调整还是无意义的。 当执行delete语句时,只会改变将隐藏字段中的删除标识改为1/true,如果后续事务出现回滚动作,直接将其标识再改回0/false即可,这样就避免了索引树的结构调整。 - **最近更新的事务ID - TRX_ID(6Bytes)** MySQL对于每一个创建的事务,都会为其分配一个事务ID,事务ID同样遵循顺序递增的特性,即后来的事务ID绝对会比之前的ID要大。 MySQL对于所有包含写入SQL的事务,会为其分配一个顺序递增的事务ID,但如果是一条select查询语句,则分配的事务ID=0。 不过对于手动开启的事务,MySQL都会为其分配事务ID,就算这个手动开启的事务中仅有select操作。 表中的隐藏字段TRX_ID,记录的就是最近一次改动当前这条数据的事务ID,这个字段是实现MVCC机制的核心之一。 - **回滚指针 - ROLL_PTR(7Bytes)** ROLL_PTR全称为rollback_pointer,也就是回滚指针的意思,这个也是表中每条数据都会存在的一个隐藏字段,当一个事务对一条数据做了改动后,都会将旧版本的数据放到Undo-log日志中,而rollback_pointer就是一个地址指针,指向Undo-log日志中旧版本的数据,当需要回滚事务时,就可以通过这个隐藏列,来找到改动之前的旧版本数据,而MVCC机制也利用这点,实现了行数据的多版本。 ##### InnoDB引擎的Undo-log日志 MySQL事务机制是基于Undo-log实现的,同时在刚刚在聊回滚指针时,聊到了Undo-log日志中会存储旧版本的数据,但要注意:Undo-log中并不仅仅只存储一条旧版本数据,其实在该日志中会有一个版本链,啥意思呢?举个例子: ```sql SELECT * FROM `zz_users` WHERE user_id = 1; +---------+-----------+----------+----------+---------------------+ | user_id | user_name | user_sex | password | register_time | +---------+-----------+----------+----------+---------------------+ | 1 | 熊猫 | 女 | 6666 | 2022-08-14 15:22:01 | +---------+-----------+----------+----------+---------------------+ UPDATE `zz_users` SET user_name = "竹子" WHERE user_id = 1; UPDATE `zz_users` SET user_sex = "男" WHERE user_id = 1; ``` 比如上述这段SQL隶属于trx_id=1的T1事务,其中对同一条数据改动了两次,那Undo-log日志中只会存储一条旧版本数据吗?NO,答案是两条旧版本的数据,如下图: 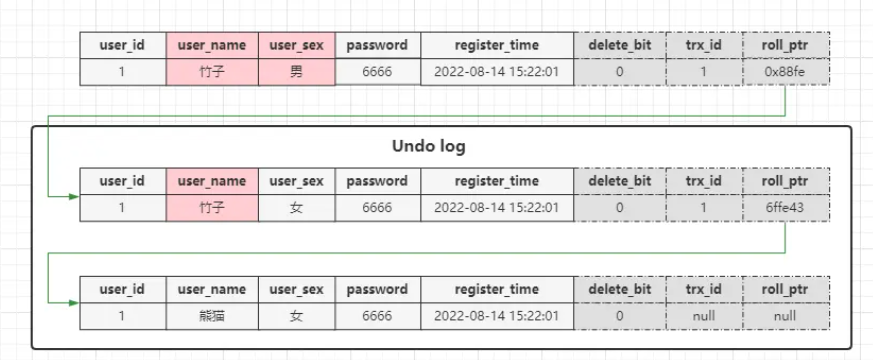 从上图中可明显看出:不同的旧版本数据,会以roll_ptr回滚指针作为链接点,然后将所有的旧版本数据组成一个单向链表。但要注意一点:最新的旧版本数据,都会插入到链表头中,而不是追加到链表尾部。 为什么Undo-log日志要设计出版本链呢?两个好处:一方面可以实现事务点回滚,另一方面则可以实现MVCC机制。 与之前的删除标识类似,一条数据被delete后并提交了,最终会从磁盘移除,而Undo-log中记录的旧版本数据,同样会占用空间,因此在事务提交后也会移除,移除的工作同样由purger线程负责,purger线程内部也会维护一个ReadView,它会以此作为判断依据,来决定何时移除Undo记录。 ##### MVCC核心 - ReadView 什么是ReadView?就是一个事务在尝试读取一条数据时,MVCC基于当前MySQL的运行状态生成的快照,也被称之为读视图,即ReadView,在这个快照中记录着当前所有活跃事务的ID(活跃事务是指还在执行的事务,即未结束(提交/回滚)的事务)。 当一个事务启动后,首次执行select操作时,MVCC就会生成一个数据库当前的ReadView,通常而言,一个事务与一个ReadView属于一对一的关系(不同隔离级别下也会存在细微差异),ReadView一般包含四个核心内容: - creator_trx_id:代表创建当前这个ReadView的事务ID。 - trx_ids:表示在生成当前ReadView时,系统内活跃的事务ID列表。 - up_limit_id:活跃的事务列表中,最小的事务ID。 - low_limit_id:表示在生成当前ReadView时,系统中要给下一个事务分配的ID值。  ### MVCC机制实现原理 将“MVCC三剑客”的概念阐述完毕后,再结合三者来谈谈MVCC的实现,其实也比较简单,经过前面的讲解后已得知: - ①当一个事务尝试改动某条数据时,会将原本表中的旧数据放入Undo-log日志中。 - ②当一个事务尝试查询某条数据时,MVCC会生成一个ReadView快照。 其中Undo-log主要实现数据的多版本,ReadView则主要实现多版本的并发控制。 ### MVCC机制篇总结 MVCC多版本并发控制,听起来似乎蛮高大上的,但实际研究起来会发现它并不复杂,其中的多版本主要依赖Undo-log日志来实现,而并发控制则通过表的隐藏字段+ReadView快照来实现,通过Undo-log日志、隐藏字段、ReadView快照这三玩意儿,就实现了MVCC机制。
顶部
收展
底部
[TOC]
目录
MySQL 事务的ACID原则
MySQL 事务的隔离机制
MySQL事务实现原理
MySQL之MVCC机制
相关推荐
MySQL教程
MySQL命令
MySQL索引
MySQL锁机制
MySQL版本特性