MySQL教程
MySQL范式与反范式
>设计DB库表结构时,有一些共同需要遵守的规范,被称为“范式”,理解并掌握这些设计时的规范,能让咱们在项目之初,设计的库表结构更为合理且优雅。数据库范式中,声名远扬的有三大范式。 ## 数据库三大范式 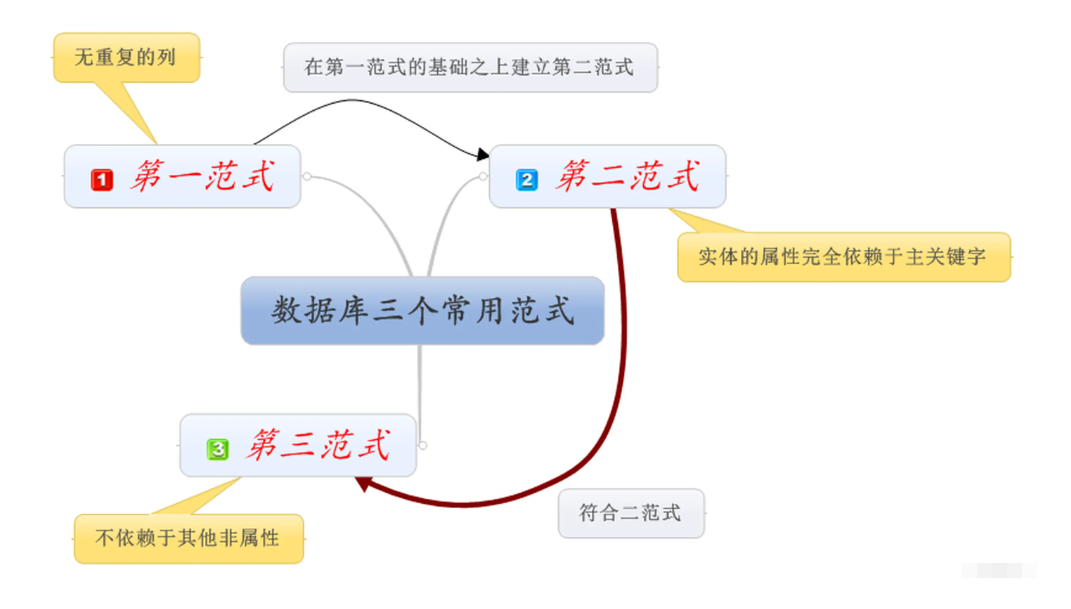 - 第一范式:确保原子性,表中每一个列数据都必须是不可再分的字段。比如身高体重是两个属性,不能划分为同一个列。 - 第二范式:确保唯一性,每张表都只描述一种业务属性,一张表只描述一件事。比如在一张描述学生成绩的表中,不应该出现一些如学生身高、体重、爱好的字段。 - 第三范式:确保独立性,表中除主键外,每个字段之间不存在任何依赖,都是独立的。比如一张学生信息表中,有他的院系及院长两个字段,因为院系及院长存在依赖关系,应该拆分。 经过三范式的示例后,数据库中的表数量也逐渐多了起来,似乎设计符合三范式的库表结构,反而更加麻烦了对吗?答案并非如此,因为在没有按照范式设计时,会存在几个问题: - 整张表数据比较冗余,同一个信息会出现多条。 - 表结构特别臃肿,不易于操作,要新增一个信息时,需添加大量数据。 - 需要更新其他业务属性的数据时,比如院系院长换人了,需要修改所有学生的记录。 但按照三范式将表结构拆开后,假设要新增一条学生数据,就只需要插入学生相关的信息即可,同时如果某个院系的院长换人了,只需要修改院系表中的院长就行,学生表中的数据无需发生任何更改。 经过三范式的设计优化后,整个库中的所有表结构,会显得更为优雅,灵活性也会更强。 ## 数据库反范式设计 遵循数据库范式设计的结构优点很明显,它避免了大量的数据冗余,节省了大量存储空间,同时让整体结构更为优雅,能让SQL操作更加便捷且减少出错。但随着范式的级别越高,设计出的结构会更加精细化,原本一张表的数据会被分摊到多张表中存储,表的数量随之越来越多。 但随之而来的不仅仅只有好处,也存在一个致命问题,也就是当同时需要这些数据时,只能采用联表查询的形式检索数据,有时候甚至为了一个字段的数据,也需要做一次连表查询才能获得。这其中的开销无疑是花费巨大的,尤其是当连接的表不仅两三张而是很多张时,有可能还会造成索引失效,这种情况带来的资源、时间开销简直是一个噩梦,这会严重地影响整个业务系统的性能。 因此,也正是由于上述一些问题,在设计库表结构时,我们不一定要100%遵守范式准则。这种违反数据库范式的设计方法,就被称之为 反范式设计。 在设计时千万不要拘泥于规则之内,一定要结合实际业务考虑,遵循业务优先的原则去设计结构。随意设计出的结构,不满足范式要求,同时还无法给业务上带来收益的,这并不被称为反范式设计,反范式设计是一种刻意为之的思想。 一般而言,库表结构设计的是否合理,区别如下: - 不合理的结构设计会造成的问题: - 数据冗余,会浪费一定程度上的存储空间 - 不便于常规SQL操作(例如插入、删除),甚至会出现异常 - 合理的结构设计带来的好处: - 节省空间,SQL执行时能节省内存空间,数据存储时能节省磁盘空间 - 数据划分较为合理,DB性能整体较高,并且数据也非常完整 - 结构便于维护和进行常规SQL操作
顶部
收展
底部
[TOC]
目录
MySQL四层架构
MySQL存储引擎
MySQL数据类型
MySQL索引
MySQL 事务
MySQL锁机制
MySQL分区分表分库
MySQL主从复制
MySQL调优
MySQL范式与反范式
相关推荐
MySQL命令
MySQL索引
MySQL事务
MySQL锁机制
MySQL版本特性